

LINE-#
1012
1012
1015
1015
1020
1020
02
03
01
02
01
02
2241
2518
1035
2518
2241
2518
200
300
150
200
10
150
6650.00
6360.00
3300.00
4240.00
3325.00
3180.00
Рис. 1.7. Файлы IPD, имеющие иерархическую структуру
На рис. 1.8 показано, как выглядит иерархия отношений между клиентами, счетами и строками счетов. Клиенту «подчинены» счета, которым, в свою очередь, «подчинены» строки. В иерархической базе данных эти три файла будут связаны между собой физическими указателями, или полями данных, добавленными к отдельным записям. Указатель - это физический адрес, означающий, где запись находится на диске. Каждая запись о клиенте будет содержать указатель первой записи счета этого клиента. В свою очередь, записи счетов будут содержать указатели на другие записи счетов и на записи строк счетов. Таким образом, система легко сможет извлечь все записи счетов и строк счетов, относящихся к данному клиенту.
Указатель -
физический адрес, обозначающий место хранения записи на диске.
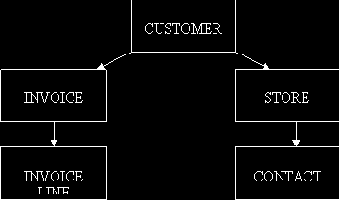
Предположим, что мы хотим добавить в нашу иерархическую базу данных информацию о клиентах. Например, если наши клиенты - торговые компании, нам может понадобиться список магазинов каждой компании. В этом случае мы расширим диаграмму, приведенную на рис. 1.8, придав ей вид, представленный на рис. 1.9. Файл CUSTOMER по-прежнему находится над файлом INVOICE, который находится над файлом INVOICE LINE. Но в то же время с файлом CUSTOMER связан файл STORE (МАГАЗИН), а с ним — файл CONTACT (ПРЕДСТАВИТЕЛЬ). Под представителем мы подразумеваем закупщика, которому продаем товары для конкретного магазина. Из этой диаграммы мы видим, что клиент является вершиной иерархии, из которой мы можем извлечь немало информации.
 |
Рис. 1.8. Иерархическая модель отношений между файлами CUSTOMER, INVOICE и INVOICE LINE
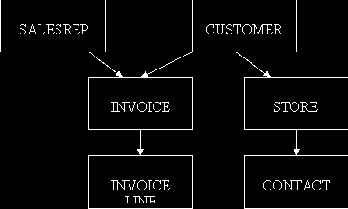
На этих диаграммах показаны те разновидности связей между файлами, которые могут быть легко реализованы в иерархической модели. Однако быстро стало ясно, что у такой модели есть некоторые существенные ограничения, поскольку не все отношения можно представить в виде иерархии. Например, вернемся к нашему примеру и сделаем следующий шаг. Очевидно, что нас могут интересовать связи не только между клиентами и счетами, но и между торговыми агентами и счетами. То есть мы хотим иметь список всех счетов на продажи, произведенные определенным торговым агентом, чтобы подсчитать сумму причитающихся ему комиссионных. Новые связи представлены на рис. 1.10.
 |
Однако эта диаграмма не является иерархической. В иерархии у каждого потомка может быть только один предок. На рис. 1.9 INVOICE - потомок, CUSTOMER - его предок. Однако на рис. 1.10 у INVOICE имеется два предка - SALES-REPRESENTATIVE и CUSTOMER. Такого рода диаграммы называются сетевыми. В связи с очевидной необходимостью обрабатывать такие отношения в конце шестидесятых появились сетевые системы управления базами данных. Как и в иерархических, в сетевых системах баз данных для связывания файлов использовались физические указатели.
 |
Потомок - подчиненная запись в иерархии.
Предок - подчиняющая запись в иерархии.
Сеть - отношения между данными, когда каждая подчинена записям более, чем из одного файла.
Основная иерархическая СУБД - система IMS фирмы IBM, созданная в середине шестидесятых годов.В конце шестидесятых - начале семидесятых были созданы и завоевали рынок несколько сетевых СУБД; стандартом для такой модели, в конце концов, стал CODASYL. В последующих главах мы обсудим обе эти модели данных, требуемые для них определения данных и возможности управления данными.