

Другие недостатки традиционных файловых систем
Несмотря на появление файлов с произвольным доступом, быстро стало очевидным, что файловые системы любого типа обладают некоторыми врожденными недостатками:
q
Избыточность данных.
q Слабый контроль данных.
q Недостаточные возможности управления данными.
q Большие затраты труда программиста.
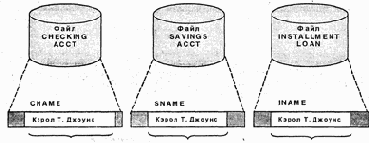
20 символов 15 символов 15 символов
Запись текущего Запись сберегательного Запись ссуды
счета счета
Рис. 1.5. Имя клиента, представленное в разных полях
Избыточность данных. Главная трудность состоит в том, что многие приложения используют свои собственные файлы данных. Таким образом, некоторые единицы данных повторяются в разных приложениях. Например, в банке одно и то же имя клиента встречается в файлах, содержащих сведения о текущих счетах, сберегательных счетах и ссудах (рис. 1.5). Более того, хотя это одно и то же имя клиента, соответствующие поля в разных файлах могут называться по-разному. Так, поле CNAME файла текущих счетов превращается в SNAME файла сберегательных счетов и в INAME файла ссуд. Одно и то же поле в разных файлах может, кроме того, иметь разную длину. Например, поле CNAME может содержать до 20 символов, а поля SNAME и INAME допускают максимальную длину 15 символов. Следствием такой избыточности данных являются лишние затраты на поддержание и хранение данных. Избыточность данных также порождает риск противоречий между разными версиями общих данных.
Предположим, что клиент изменил имя с Кэрол Т.Джоунс на Кэрол Т.Смит. Изменение могло быть сразу внесено в файл текущих счетов, через неделю - в файл сберегательных счетов, а в файл ссуд изменение могло оказаться внесенным неверно - Кэрол Т.Смит (рис. 1.6). По прошествии некоторого времени подобные расхождения могут существенно снизить качество информации, содержащейся в файлах данных.
Такая несогласованность данных может также отразиться на точности отчетов. Предположим, что вы хотите составить отчет, в котором должны
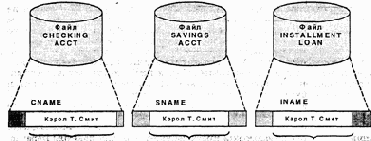
20 символов 15 символов 15 символов
Запись текущего Запись сберегательного Запись ссуды
счета счета
Рис. 1.6. Неверные изменения имени клиента
быть перечислены все клиенты, имеющие текущие счета или сберегательные счета, которые брали у банка ссуды. Кэрол Т.Смит будет пропущена в этом отчете, поскольку в файле ссуд ее имя выглядит как Кэрол Т.Смит. Как мы вскоре увидим, информационные системы, использующие базы данных, позволяют избавиться от подобной избыточности данных, поскольку все приложения используют один и тот же набор данных. Существенная информация, например, имя или адрес клиента, будет записываться в базе данных всего один раз. Таким образом, мы сможем изменять адрес или имя клиента один раз, будучи при этом уверены, что все приложения будут пользоваться согласованными данными.
Слабый контроль данных. В файловых системах, как мы уже успели заметить, отсутствует централизованный контроль на уровне элементов данных. Весьма часто один и тот же элемент данных имеет несколько имен в зависимости от того, в какие файлы он входит.
На более фундаментальном уровне всегда существует вероятность того, что разные отделы компании пользуются терминологией, не согласованной с остальными. Например, банк может вкладывать в термин счет один смысл применительно к сбережениям и совсем другой применительно к ссудам. Разные значения одного и того же термина называются омонимами. И наоборот, разные слова могут иметь одинаковые значения. Страховая компания может говорить о владельце полиса или о клиенте, вкладывая в эти два термина один и тот же смысл. Термины, имеющие одно и то же значение, называются синонимами. Система управления базами данных осуществляет централизованный контроль данных и помогает избежать недоразумений, порожденных омонимами и синонимами.
Омонимы - разные значения одного и того же термина.
Синонимы -
термины, имеющие одно и то же значение.
Недостаточные возможности управления данными. Индексно-последовательные файлы позволяют обращаться к определенной записи по ключу, например, по идентификатору товара. Например, если мы знаем идентификатор настольной лампы, мы можем напрямую извлечь из файла PRODUCT относящуюся к ней запись. Этого достаточно до тех пор, пока нам нужна отдельная запись.
Однако предположим, что нам нужен целый ряд связанных между собой записей. Например, мы хотим найти все продажи клиенту Мальтц. Допустим, что мы также хотим узнать общее число таких продаж, среднюю цену или же список товаров, купленных клиентом и кто является изготовителем этих товаров. Такую информацию будет трудно, если не невозможно, извлечь из файловой системы, поскольку файловые системы не позволяют устанавливать связь между данными разных файлов. Системы управления базами данных были специально разработаны для того, чтобы упростить связывание данных из разных файлов.
Большие затраты труда программиста. Новая прикладная программа часто требовала совершенно нового набора файлов. Даже если существующий уже файл содержал некоторые нужные данные, приложению часто требовался еще какой-либо набор элементов данных. В результате программисту приходилось перекодировать определения нужных элементов данных из существующих файлов, а также определять новые элементы данных. Таким образом, в файловой системе существовала жесткая зависимость между программами и данными.
Что еще более важно, манипулирование данными в файлово-ориентированных языках (таких как Кобол) было слишком сложным для создания больших приложений. Это означало, что затраты труда программиста как на создание приложения, так и на поддержание его работы были весьма значительны.
Базы данных позволили разделить программы и данные, так что программа может быть в некотором смысле независима от
2. Реляционная модель данных